Assisting Accountants with Zero-shot Machine Learning
It seems like Zero-Shot Classification should be impossible, right? How could a machine learning model classify an object with a label that it has never seen before?
Traditional classification involves lots of labeled examples, but the trained model is limited to the set of labels from the training set. How, on earth, could we train a model to emit a label that is completely novel? With the rise of Large Language Models (LLMs), there is a new path on this quixotic quest. Numerous problems are being tackled creatively through prompt engineering of the input to these models, from coaxing out the perfect image from DALL-E or learning to beat humans in conversational games (for example: Cicero). By following these lateral uses of the model, we can find our way to classifying objects with labels the model has never seen before.
Business Problem
A core function of accounting is proper labeling (aka "coding") of transactions. The accuracy of this step is crucial for building actionable financial reports for the stakeholders of a company. The process of labeling each individual transaction that crosses a company’s books is painstaking and traditionally very manual. More recently, tools have been developed to bucketize some subset of transactions via some hand-crafted heuristics based on the vendor or the description of the transaction. But these tools often fall short as they don’t have enough information to accurately label them automatically. For the transactions that fall through, the accountant must manually triage each one. Often, the accountant must seek further clarification from the client about the transaction, such as what was purchased, or the intended use of the item, or even who was present, to make an accurate decision on how to book it.
Machine learning is perhaps an obvious tool to aid this flow, but it does run into trouble. Within the accounting world, the labels chosen for transactions are consistent per accountant/client relationship but often globally inconsistent. So, what helps speed one accountant becomes a roadblock for another.
Similarity as First Pass
As we’ve talked about in other blog posts (part 1 and part 2 ), we use the similarity of generated embeddings to automatically label transactions. By casting a transaction description to a vector via a trained embedding model, we can find highly-similar transactions and then look up how they were labeled by the accountant (or other algorithms) in the past. But this falls down in 2 main cases.
- A common transaction, easily identifiable, is attributed to multiple use cases, such as an Amazon purchase. It could be practically any label as Amazon sells such a diverse range of products.
- A completely unidentifiable transaction, such as a check or an unlabeled invoice.
Both of these cases could return multiple possible labels via the similarity approach, just as an accountant may mentally call up the common past labels for this type of expense.
The next step in many accountants’ workflow is to seek out more information from the client. Through the responses, the accountant hopes to gather enough context to correctly label the transaction in the books. Here is where Zero-Shot Classification can help!
Our Approach
Large language models are trained on multiple tasks simultaneously to generate an “understanding” of a language. One of the common training tasks is entailment. Entailment is the concept that one sentence directly follows from another. For example:
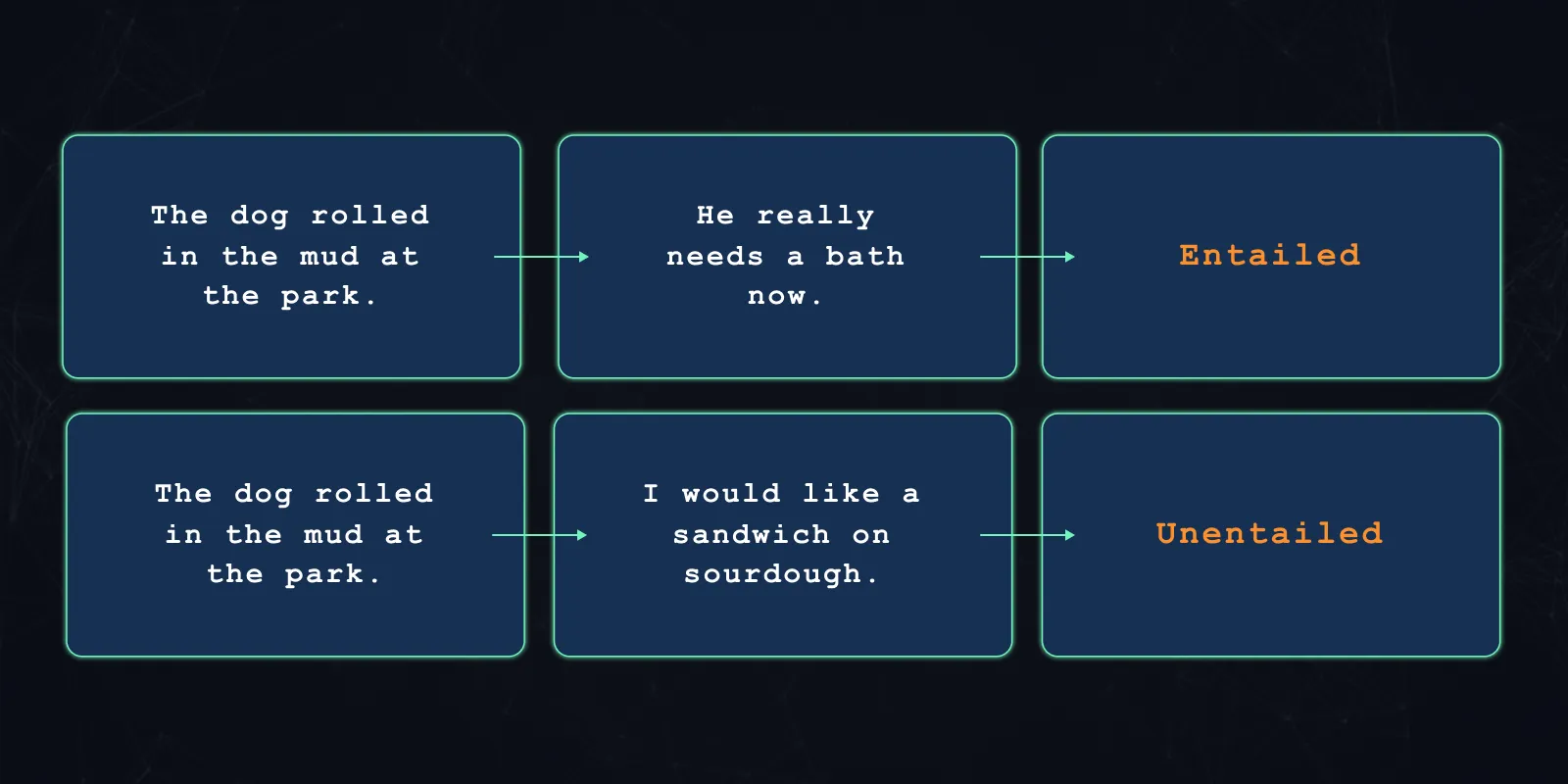
Through some careful prompt-engineering we can leverage this understanding to generate an ad-hoc classifier.
We start with the transaction and our similarity model. Then, from all the related transactions and their past encodings we get a list of candidate categories: our possible labels.
We then take the transaction, the accountant’s question, and the client’s response and compose a sort of narrative by concatenating them.

We then create a set of “hypothesis” statements from the candidate categories. For each we use the same template and we get something like:
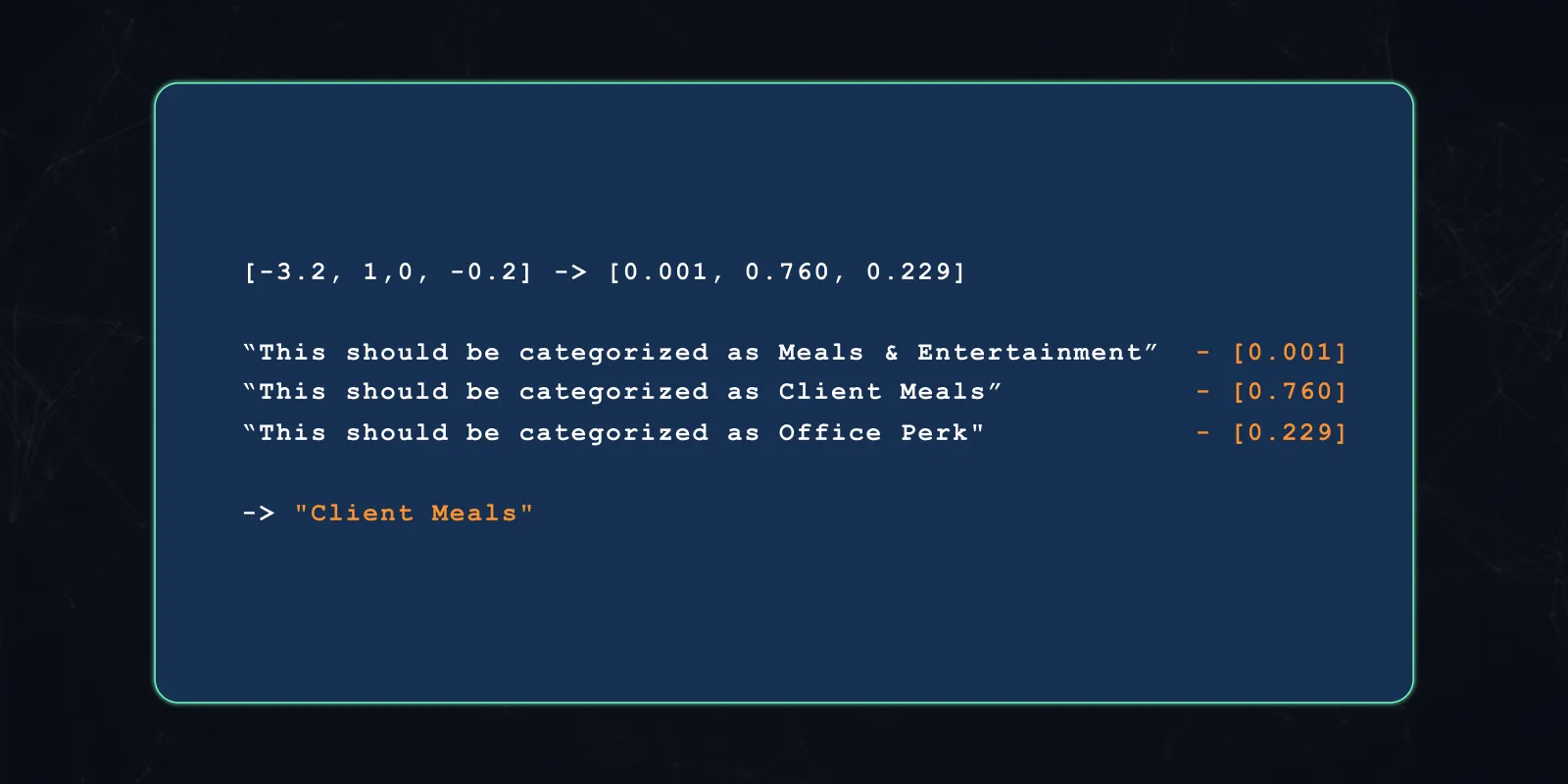
Then, for each pair of “narrative” and “hypothesis”, we query the model and get an entailment score.

Then we simply take the softmax of the resulting scores! The highest score is the model’s prediction:

Through this approach, we’ve successfully used a machine learning model to produce a classification label without having to explicitly train a model to output the label “Client Meals”. All through the power of a Large Language Model and its facilities with natural language.
Providing this parsed result to the accountant saves them valuable time, in that they don’t have to context switch into each transaction. And for each example the accountant accepts or rejects, we get a further training example to fine tune the base entailment model into the domain of our users.
Next Steps
- Further fine-tuning the model is an ongoing process as we collect more examples, and users, over time
- Validating the output of other classification models
- Continue exploring the myriad uses of LLMs as they come to light
Final Thoughts
Over the course of this three part series (part 1 and part 2 ), we discussed just one of the many flows powered by machine learning at Digits, always with a focus on empowering accountants and their clients. We showed how we classify transactions within the domain of a specific accountant/client relationship using Similarity-based Machine Learning. We demonstrated using generative models to speed boost accountant-client communication without imposing chat-bots on customers. And here we explored how we can parse the natural language of conversation to automatically make a category classification with a model that has no prior knowledge of the codings it has to choose from.
Further Reading
If you are interested in zero-shot learning, we can recommend the following resources: