Digits + Karbon: Practice Management Meets the Ledger That Closes the Books
Digits partners with Karbon to bring practice management closer to the ledger, helping firms connect client work with cleaner accounting data.
 Connect your firm stack to Digits—New partnerships with: Ignition, Karbon, Reach Reporting.
Connect your firm stack to Digits—New partnerships with: Ignition, Karbon, Reach Reporting.
Digits partners with Karbon to bring practice management closer to the ledger, helping firms connect client work with cleaner accounting data.

Digits partners with Reach Reporting to turn cleaner, more current ledger data into client-ready reports, dashboards, and budgeting workflows.

Digits partners with Ignition to connect revenue workflows and the ledger, helping firms automate billing data flow and unlock future insights.

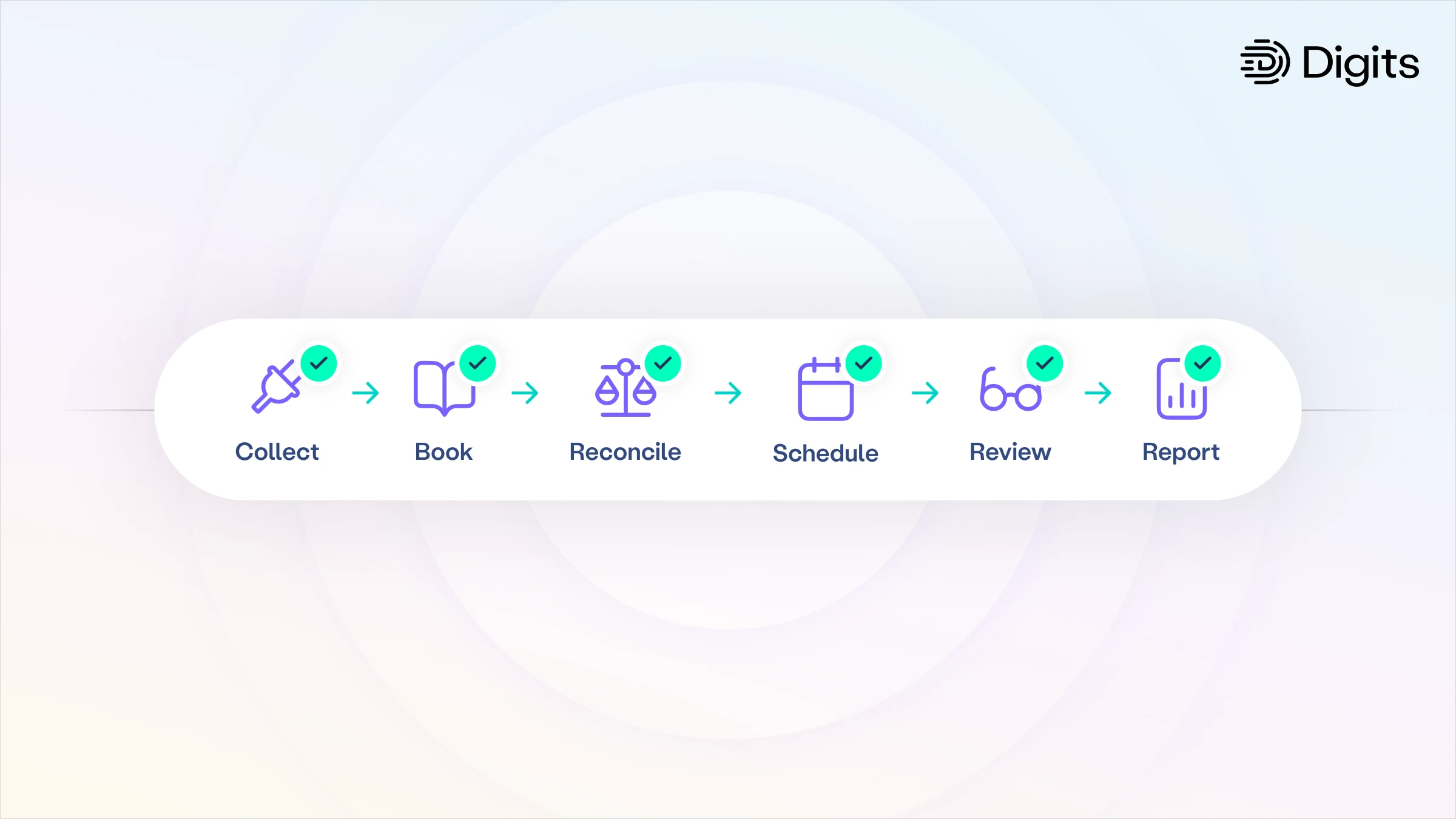
Digits Agentic Close continuously books, reconciles, schedules, and reviews financial activity, surfacing exceptions in Checklist for accountant review.

Frontier AI now beats human accountants at classification, but the real accounting advantage is purpose-built systems that help close the books.

Digits is now programmable: Connect API opens the AGL to developers with AI-led categorization, vendor matching, reconciliation, and dimensional accounting.

Digits now connects to 18 more payroll providers, automatically posting payroll into the Agentic General Ledger™—no CSV exports, no manual journal entries, no reconciliation headaches.

Digits AI Bank Reconciliations automatically reconcile bank statements, flag anomalies, and tie out balance sheet accounts. Drop in a PDF statement—Digits handles the rest.
Unsubscribe anytime.

When everyone can build with AI, the bottleneck shifts. Here's how Digits built the infrastructure that turned ideas into trusted internal software.

AI made building software easy. Maintaining it is another story. Why accounting firms should build what makes them unique and buy the rest.
