ChatGPT for Accounting: How Digits is using Generative Machine Learning to transform finance
ChatGPT, one of the largest and most sophisticated language models ever created, has recently become a household topic of conversation. If you've been wondering how this incredible technology can be applied to the accounting and finance space, this is the article for you :)
Welcome to chapter two of our three-part series on machine learning! We kicked off with an introduction to similarity-based machine learning, and how we apply it to accounting use cases at Digits. Today, let's explore generative machine learning and what it can bring to the accounting world.
Generative machine learning has received significant attention because it opens up a completely new field of "AI". It is getting closer to fulfilling the human dream of teaching machines some form of “creativity.” Model architectures like ChatGPT, DALL-E, and T5 have provided solutions to various problems including writing text, generating photo-realistic images, and summarizing complex topics. In this blog post, we are excited to explore machine learning for natural language generation and how we are using these concepts today at Digits.
What is Generative Machine Learning?
Traditionally, machine learning has been applied to classification problems, where you take some text and distill it into different buckets or categories. You can think of the text as being "encoded" into those categories. For years, the dream has been to push beyond that, and train a machine learning model that can actually generate text, rather that just classify it. How might that work?
Researchers began building on this approach by experimenting with model architectures that first reduce information through a model encoder and then “decompress” the information back into human-readable text through a decoder. They made a significant breakthrough in 2017 when they presented an encoder-decoder model architecture called Transformer.
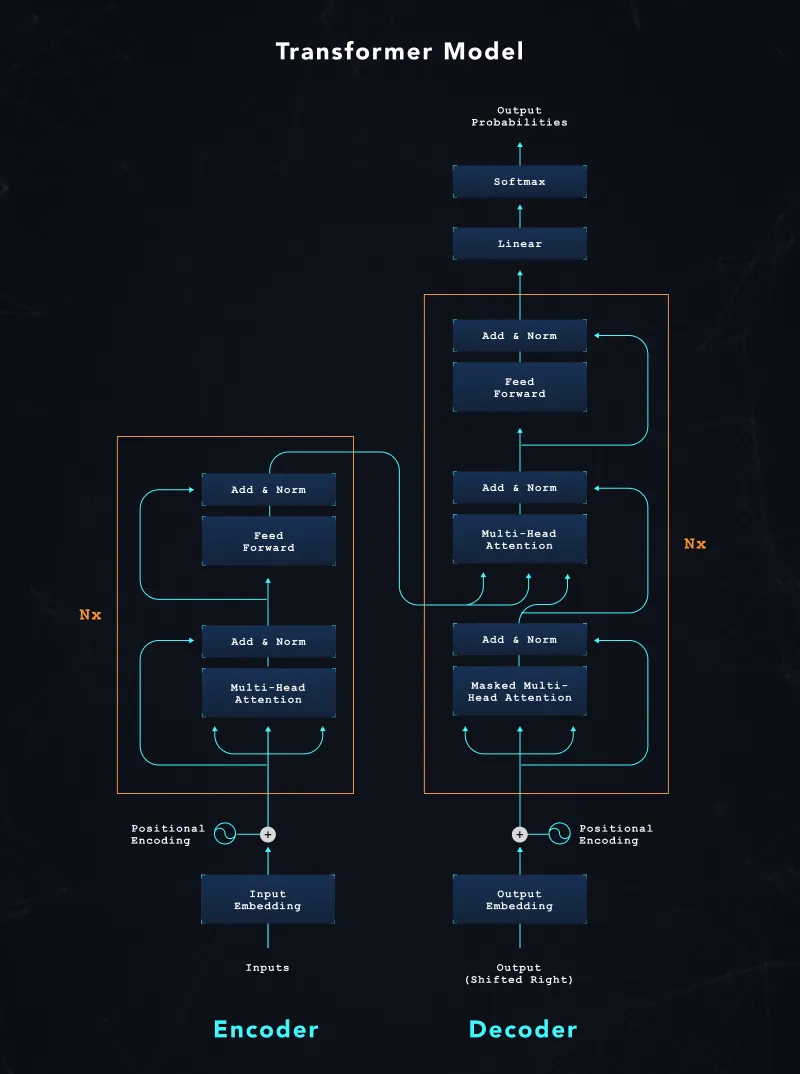
The model architecture shown above shows the encoder (left side) – decoder (right side) structure. Over the last few years, researchers further refined this architecture by increasing the number of model weights, which allows capturing more “knowledge” into the model, and by fine-tuning the decoder side to respond to decoder “instructions.” The fact that models can now use “instructions” as model inputs unlocked meta-learning, where a model can generate text for untrained scenarios. For example, we can train a model on translating English-German and English-French, and through “instructions,” the model can then be prompted to translate between German and French.
To generate text for a given input text, the decoder model uses the reduced information as an embedding it obtains from the encoder and the initial instruction to generate the first-word token for the generated text. Then it uses the newly generated token together with the instructions and the embedding to generate the second-word token for the text. This generation loop continues until the decoder has reached its maximum sequence lengths (usually 512 or 1024 tokens) or the decoder produces a stop-token instructing the decoder that any text generated following is considered padding. The generated text will then reflect the model’s response to the input text and the given instruction. Here is an example: