
Architecting Digits Search: Real-time Transaction Indexing With Bleve
We recently launched Digits Search, which brings fast, beautiful, full-depth search to business financial data. We’ve received a ton of great customer feedback, but one question just keeps coming up…
How did you build this!?
Well, let’s break down how Digits Search puts your finances at your fingertips.
Digits Architecture
First, some quick background on Digits:
Digits links with your business’ accounting software and your financial institutions to build, and continually maintain, a living model of your business with the most up-to-date data. Once linked, we ingest all of that financial data in raw form, a collection that we call “facts”.
We then use machine learning and data processing to normalize all of that overlapping, unstructured data. We perform a significant number of calculations to fill holes in the picture, such as predicting how your latest transactions will be categorized, detecting and predicting recurring activity, etc.
The end result of all this work is a “view”, which is then efficiently loaded into Google Cloud Spanner as well as encrypted and archived in Google Cloud Storage for secondary processing.
Each view we produce is a complete, standalone picture of your company’s entire financial history.
Views are served by our serving layer, which is composed of a number of services communicating over TLS-encrypted GRPC APIs, written in Go and hosted in GKE. Our serving layer aims to optimize for efficiency, security, and reliability.
Architecting Search
There are a great many open-source search tools available. Examples range from library implementations like Lucene, server implementations like Solr, clustered solutions like ElasticSearch, and SaaS solutions like Algolia.
To pick a direction, we thought about how each approach would integrate with our existing Digits architecture.
The most important architectural factor for our design is our complete, standalone view production every time we get new data. This architectural bedrock presents us with some significant design opportunities:
- Each View is complete and self-contained, which allows for indexing to be done entirely offline and for each view index to be immutable.
- Each View is a natural sharding element, which is independent from other views, even for the same business.
- The immutable nature of views and their indexes allows us to think of indexes as deliverable objects, rather than as online mutable state.
With this framing in mind, we began to look for a solution that would allow us to produce offline indexes and reliably serve them from within our current serving layer.
Ideally, this solution would integrate seamlessly with our existing services: Go, GRPC with mTLS, stateless authorization for bulletproof multi-tenancy, minimal GKE footprint, and minimal operator overhead. In particular, mutual TLS and token authentication are part of our system design at every layer of the stack, and act as defense-in-depth measures against pivots within our infrastructure in case of a breach. Any solution we pick for search must support this level of data protection.
It should also be as fast as the dickens.
We took stock of the various search strategies (clusters, servers, libraries, SaaS), and researched options within each space. We found that many solutions are organized around managing updates to online, mutable indexes. However, our view-based architecture allows us to skip over many of the state-management concerns (and the operational overhead) that mutable indexes must handle.
We decided that the library strategy appeared most promising, as it would allow us to take strong advantage of the near-statelessness of offline index shipping. The library approach would also allow us to use our existing common service code and configurations to keep operational overhead low.
Apache Lucene regularly tops the list of open source search libraries, but an ideal solution would be able to leverage all of our experience-hardened service code in our Go monorepo. We’ve strongly prioritized security in our system designs, and being able to leverage our existing, penetration-tested code for authorization, encryption, and network services would help us continue to keep our systems secure. With that in mind, we surveyed the current search landscape in Go, and immediately found a promising option!
Enter: Bleve, a native-Go search library that underpins major projects such as Couchbase and Caddy.
We tried some quick experiments to see if Bleve was suited to our needs, and we were very pleased to learn that it exceeded our expectations! We then built a more complete prototype and quickly demonstrated that it was a great fit.
With our starting strategy in mind, we then began to flesh out the system’s overall design.
The views themselves would be produced by our streaming and batch pipelines. To ensure the work of indexing our views wouldn’t impact query latency, we wanted to index the data offline, separately from the serving processes. This meant we’d need a way to reliably deliver each completed index to the serving boxes. Finally, we’d also need a service for query processing and to coordinate future sharding. To coordinate the encrypted data moving between systems, Google Cloud PubSub and GCS were our first choice, as we had experience with them elsewhere.
Here’s a quick look at the design we’ve sketched out so far:
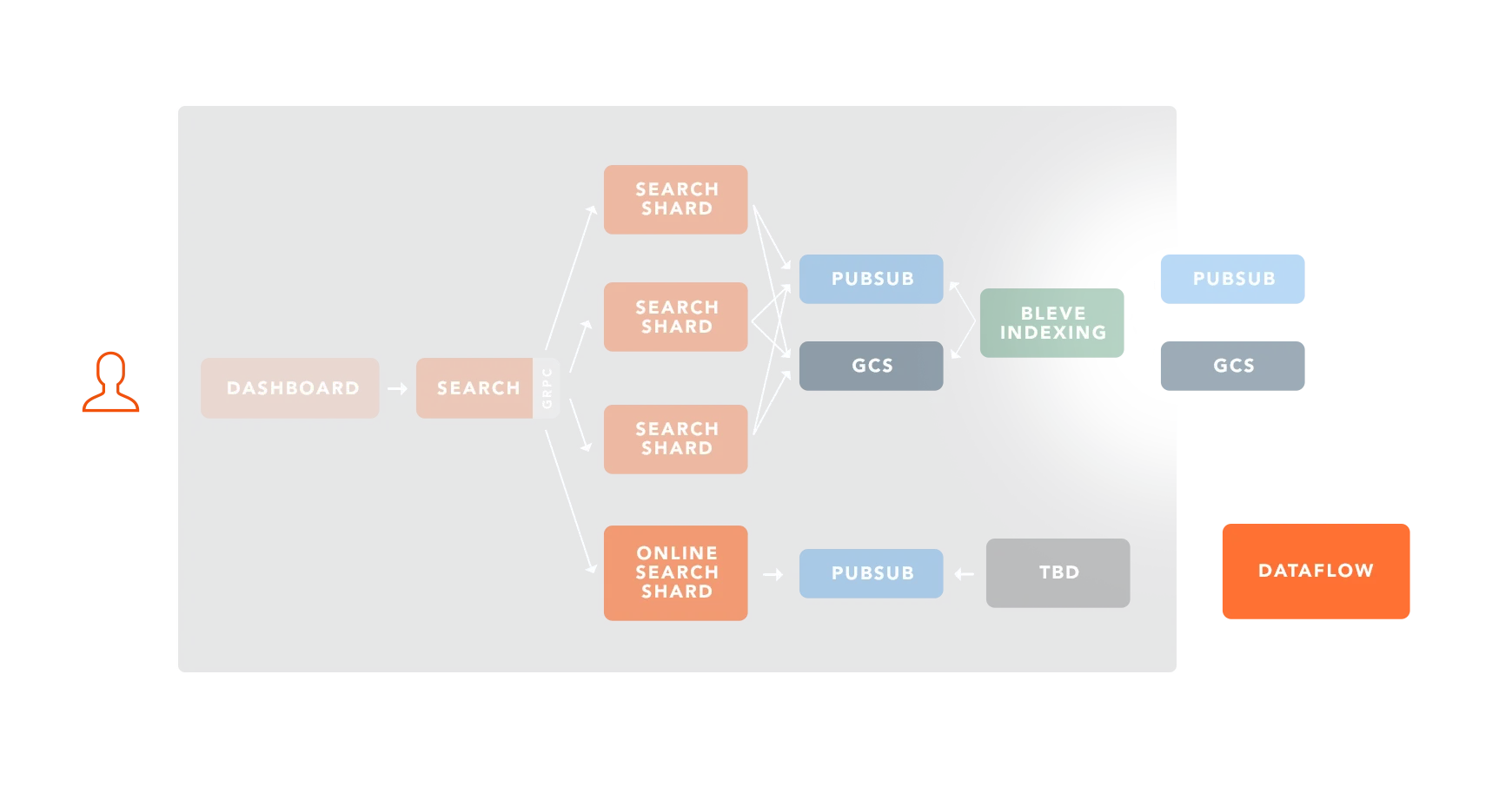
Although this might seem like a lot at first blush, each of these services serves a specific purpose, and our Go monorepo automation makes managing them easy and lightweight.
Each service is deployed to GKE via our continuous deployment pipeline and uses common, shared service and GRPC libraries we’ve built to ensure all of our services operate in a consistent, secure manner. Standing on the shoulders of giants, the completed search system amounts to less than 5,000 lines of code, including custom query pre-processing, document handling, and integration tests.
Building Search
Search must address a number of sub-problems: document collection, mapping, and indexing; index storage and cleanup; query pre-processing and routing; and result delivery. To see how this all comes together, we’ll walk through the Indexing and Serving parts of Search.
One thing we learned about Bleve is that while the basic documentation is excellent, the project has added a number of interesting features and optimizations which are not mentioned in the published documentation, but are instead discussed on the mailing list or in Github issues. As we go along, we’ll include code snippets to highlight those additional features as we’ve used them.
Secure Indexing
To build our indexes, we first need to assemble the raw data from the views we produce, a process we call “bundling”. Bundling brings together multiple distinct document types, for example, vendors, categories, and transactions. These document collections are encoded as Protobuf, archived, and encrypted, waiting for our search indexer to retrieve them from Google Cloud Storage.
type Bundle struct {
LegalEntityID string
ViewVersion float64
Vendors []*search.ArchiveVendor
Transactions []*search.ArchiveTransaction
Categories []*search.ArchiveCategory
}
To populate the Bundle, we download our archives from GCS and decrypt them. Once we’ve got everything in one place, we’re almost ready to index.
But, before we can proceed, we need to tell Bleve how to handle each of our document types. Bleve calls this process mapping, and we’ll need to configure our overall index, document types, and their fields. At the top, we create our IndexMapping(), and add each of our Document types to it:
func (b Bundle) mapping() (mapping.IndexMapping, error) {
// Base Index Mapping for this Bundle
m := bleve.NewIndexMapping()
// Each new type this bundle supports must
// be added here, which will in turn expose
// it's mapping to the indexer.
types := []document.Mappable{
&document.Transaction{},
&document.Vendor{},
&document.Category{},
}
// Iterate over the provided mappable types
// and map them.
for _, t := range types {
m.AddDocumentMapping(t.Type(), t.DocumentMapping())
}
return m, nil
}
Each of our supported document types implements our Mappable interface, which returns their DocumentMappings, and in turn, their relevant FieldMappings:
func (t *Category) DocumentMapping() *mapping.DocumentMapping {
doc := t.Extractable.DocumentMapping()
// Disable fields that should not be searched/stored in the index
doc.AddSubDocumentMapping("category_id", disabledField)
doc.AddSubDocumentMapping("display_key", disabledField)
doc.AddSubDocumentMapping("type", disabledField)
doc.AddSubDocumentMapping("parent_category_id", disabledField)
doc.AddFieldMappingsAt("name", simpleMapping, minimalMapping, whitespaceMapping)
// Add date as a field mapping to this document
doc.AddFieldMappingsAt("date", t.Date.FieldMapping())
// Add keywords as a field mapping to this document
doc.AddFieldMappingsAt("keywords", t.Keywords.FieldMappings()...)
return doc
}
There’s a few interesting things happening in this example.
First, we create an Extractable as our base DocumentMapping. Each of our documents embeds Extractable, which allows us to store a protojson encoded copy of our document in a stored field in Bleve. We take this step because it allows us to build our response entirely from search results without calling other systems, which is important for keeping response latencies low. Our Extractable documents also set up type faceting, which lets us count results by type.
// Extractable represents non-indexed fields for being able to extract
// documents from a Bleve index
type Extractable struct {
Source string `json:"_source"` // must be string not bytes, https://groups.google.com/forum/#!topic/bleve/BAzJolSqhwU
DocType string `json:"_type"`
Encoding string `json:"_encoding"`
}
// DocumentMapping returns a DocumentMapping for Extractable types.
func (Extractable) DocumentMapping() *mapping.DocumentMapping {
doc := bleve.NewDocumentMapping()
// storeOnly is a text field mapping that results in a copy
// of the field being stored along with the rest of the document
// in the index, but not actually included in a searchable way.
storeOnly := bleve.NewTextFieldMapping()
storeOnly.Index = false
storeOnly.IncludeInAll = false
storeOnly.IncludeTermVectors = false
storeOnly.DocValues = false
// _source and _encoding are both used to reconstitute the original
// object from proto-as-json encoded data in search results.
doc.AddFieldMappingsAt("_source", storeOnly)
doc.AddFieldMappingsAt("_encoding", storeOnly)
// faceting is a text field mapping that is as close to storeOnly
// as possible, but with features required for faceting enabled.
faceting := bleve.NewTextFieldMapping()
faceting.Index = true
faceting.IncludeInAll = false
faceting.IncludeTermVectors = false
faceting.DocValues = true
// _type is the document type field. We facet on this to be able
// to answer the question "how many Category results came back for
// this query?"
doc.AddFieldMappingsAt("_type", faceting)
return doc
}
Returning to our Category DocumentMapping example, we also disable a number of fields from being searchable (in effect, leaving them as store-only fields in our Extractable). For the “name” field, we apply multiple different mappings, applying different analyzers, which ensures that the field is indexed in ways that are intuitively searchable to our customers. Finally, we set up some additional field mappings from some common Date and Keyword types. Every document type we currently support is sortable by date, which allows us to promote more recent documents in the results.
With our bundle populated and our mappings in place, we are ready to index!
First, we’ll create a new index using Bleve’s offline IndexBuilder. IndexBuilder optimizes the performance of creating an index, as well as the resulting files—a good match for our immutable offline indexes.
// NewIndex returns an empty index ready for indexing of this bundle
func (b Bundle) NewIndex(storePath string, batchSize int) (bleve.Builder, error) {
mapping, err := b.mapping()
if err != nil {
return nil, err
}
path := b.VersionPath(storePath)
// Create an index build directory within the storePath, which avoids
// issues within Docker containers when Bleve compacts the final index
// segments.
if err := os.MkdirAll(b.TempPath(storePath), 0775); err != nil {
return nil, err
}
config := map[string]interface{}{
"buildPathPrefix": b.TempPath(storePath),
}
// Pass through provided batch size if set,
// otherwise allow Bleve to fall back to the
// internal default batch size.
if batchSize > 0 {
config["batchSize"] = batchSize
}
// Builders only support offline indexing.
return bleve.NewBuilder(path, mapping, config)
}
Bleve’s IndexBuilder also accepts a map of string-based configuration options, which we can use to tune the batch size of indexing to make sure our indexes build quickly.
Finally, actually indexing all of our documents is a range over a channel of indexable documents.
func (idx *Indexer) builder(index bleve.Builder, documents document.Stream, legalEntityID string) error {
start := time.Now()
count := 0
for doc := range documents {
// Skip documents with empty IDs
if doc.ID() == "" {
continue
}
// Add document to index
if err := index.Index(doc.ID(), doc); err != nil {
return err
}
count++
}
// After indexing is complete, close the index to ensure that the
// file handle is released and bleve stops attempting to modify
// segments prior to us compressing/deleting the file.
if err := index.Close(); err != nil {
return err
}
logger.Infof("indexed %d in %s for %s", count, time.Since(start), legalEntityID)
return nil
}
Once we’ve generated our indexes, we ship them off to the serving boxes by encrypting them and placing them in GCS. We ensure that each serving box receives a copy of the newly-produced index by placing an event into PubSub with subscriptions configured in a “broadcast” pattern.
We’ve also added some safety mechanisms to handle edge cases, such as if a request arrives for an index that’s not present on the serving box, as well as by utilizing Kubernetes StatefulSets to keep the current index set around between deployments.
Querying
With our indexes built and ready to receive requests, let’s take a look at the query side of Search.
Bleve offers a built in query language called Query String Query, which is interpreted by the Bleve libraries and exposes a moderately-powerful interface into Bleve. However, it’s possible for your application to outgrow Query String Query. Fortunately, Bleve offers a powerful and composable API to express more complex queries.
This enables us to expose a search API customized to searching Digits, and to express constraints as distinct, typed API fields, rather than requiring them to be built into a single query string.
message EntityRequest {
// legal_entity_id and view_version are required to route search
// queries to the correct index.
string legal_entity_id = 1;
string view_version = 2;
// The object kind for the query
object.v1beta1.ObjectIdentifier.Kind kind = 3;
// The user-entered query text, unmodified.
string text = 10;
// Date range support for constraining query results.
digits.v1.Timestamp occurred_after = 20;
digits.v1.Timestamp occurred_before = 21;
// page supports query pagination
digits.v1.Pagination page = 30;
}
We are also able to perform some pre-query analysis of the user-entered text to further customize the results. For example, if we determine that the user is searching for a currency amount, we can constrain that to only search against currency fields in the index.
Although some of our SemanticQuery implementation overlaps with Bleve’s different query types, performing pre-query analysis lets us highly-customize how we handle different inputs.
// SemanticQuery is an analyzed query string with semantic tokens extracted.
type SemanticQuery struct {
Phrase string
Terms []string
Keywords []string
Quoted []string
Amounts []float64
}
Notably, we also wire up our own Stop Words that remove accounting-specific terms from queries to help focus on what the user is actually looking for:
// Custom Digits-specific stopwords
StopWords.Add(
// Spending: consider focusing searches with these terms to expenses?
"spend", "spent", "money", "pay",
// Time: consider interpreting and limiting queries
"year", "month", "day", "week", "quarter",
// Aggregations:
"total",
)
We then assemble a Bleve Boolean query from our extracted query parts:
// BuildBooleanQuery assembles a BooleanQuery from our common query arguments.
// Additional query requirements can be added to the returned object as needed.
func BuildBooleanQuery(args BooleanQueryArguments) *query.BooleanQuery {
// Extract SemanticQuery from query string.
sem := ExtractSemanticQuery(args.GetText())
// Instantiate our core BooleanQuery object, to which
// we will add parameters/requirements.
boolean := bleve.NewBooleanQuery()
// Add per-term queries for our semantic terms
terms := bleve.NewBooleanQuery()
for _, t := range sem.Terms {
// Our terms must at minimum be a subset of something in the index
prefix := bleve.NewPrefixQuery(t)
terms.AddMust(prefix)
// Exact matches are preferred
term := bleve.NewTermQuery(t)
boolean.AddShould(term)
// As are name matches
namePrefix := bleve.NewPrefixQuery(t)
namePrefix.SetField("name")
boolean.AddShould(namePrefix)
}
keywords := bleve.NewBooleanQuery()
for _, t := range sem.Keywords {
// Our terms must at minimum be a subset of something in the index
prefix := bleve.NewPrefixQuery(t)
keywords.AddMust(prefix)
}
// Add our terms and keywords multiple ways:
switch {
case sem.HasTerms() && sem.HasKeywords():
// If we have both terms _and_ keywords, run them as a disjunct query
disjunct := bleve.NewDisjunctionQuery(terms, keywords)
boolean.AddMust(disjunct)
case sem.HasTerms():
// If we only have terms, run just the terms
boolean.AddMust(terms)
case sem.HasKeywords():
// If we only have keywords, run just the keywords.
boolean.AddMust(keywords)
}
// Add specific handling for quoted terms
for _, q := range sem.Quoted {
quoted := bleve.NewMatchPhraseQuery(q)
boolean.AddMust(quoted)
}
// Add specific handling for formatted amounts if detected.
for _, amt := range sem.Amounts {
// Ranges should be inclusive so the same value for min and max
// will find the correct results.
inclusive := true
// Capture the loop variable because we must take it's address.
amount := amt
// Search for this amount numerically. Range must be inclusive to support
// searching precise amounts.
numAmount := bleve.NewNumericRangeInclusiveQuery(&amount, &amount, &inclusive, &inclusive)
numAmount.SetField("num_amount")
// Search for this amount numerically against absolute values. Range must
// be inclusive to support searching precise amounts.
absAmount := bleve.NewNumericRangeInclusiveQuery(&amount, &amount, &inclusive, &inclusive)
absAmount.SetField("abs_amount")
amounts := bleve.NewDisjunctionQuery(numAmount, absAmount)
boolean.AddMust(amounts)
}
return boolean
}
We have additional query-building logic to further constrain queries by date, page, and type.
We then route our built query to our serving shards, await the results, and convert them to our protobuf response type:
// Result represents a customer-facing set of search results.
message Result {
// The number of results
int64 total = 1;
// The hits for this page of results
repeated Hit results = 2;
// The count by ObjectEntity.Kind of the results for this query.
repeated ObjectKindFacet kind_counts = 3;
// The amount of time to retrieve the results from the index.
double took_secs = 4;
// The hydrated objects referenced in results above
object.v1beta1.ObjectEntities entities = 10;
}
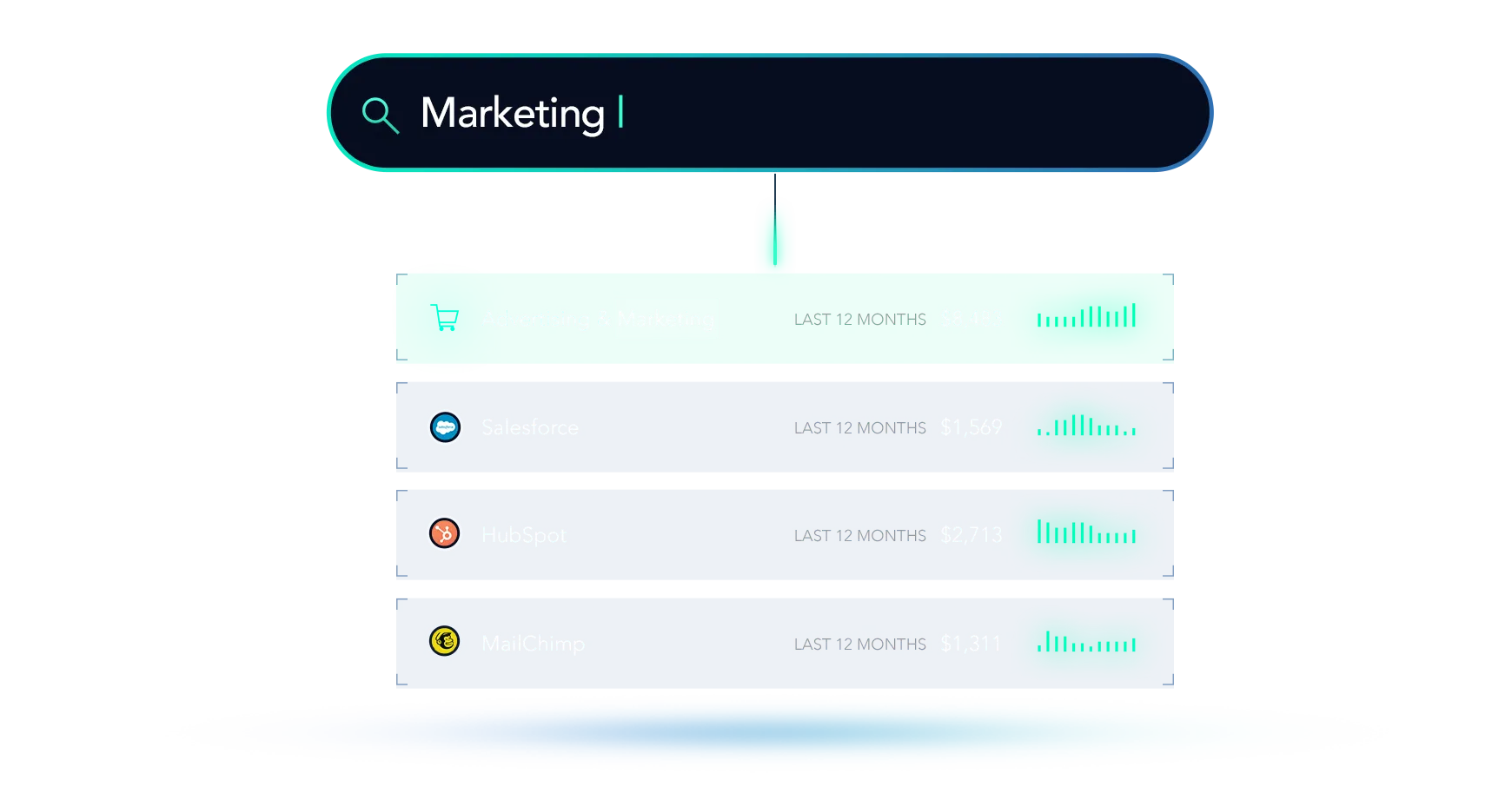
And with that, we’re able to then render these results in Digits!
Results
We’re extremely happy with Digits Search.
What began as a companion feature quickly proved it’s value and became our first public launch. Although search functionality exists today in nearly every app and website, the power of Digits brings deep, full-history search to finances in a way that hasn’t existed before.
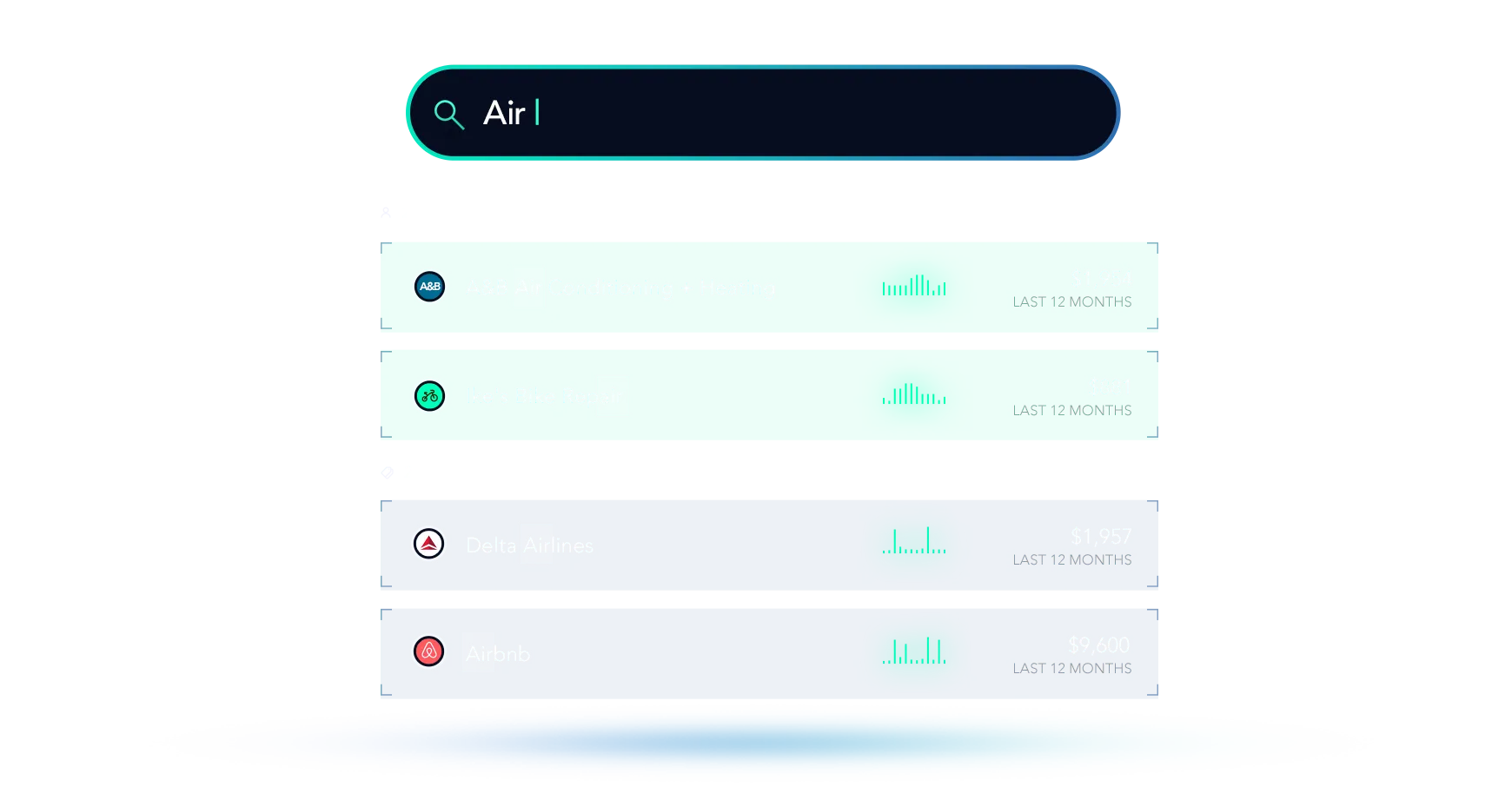
Furthermore, we’re especially pleased with Search (and Bleve’s) performance. Our typical response time, even for very large customers, is under 50ms.
We use Google Cloud Trace to inspect requests and to ensure we can respond to performance issues. Visualizing the requests made to build the page in the screenshot above highlights how quickly we’re able to assemble the parts of the page into a response:
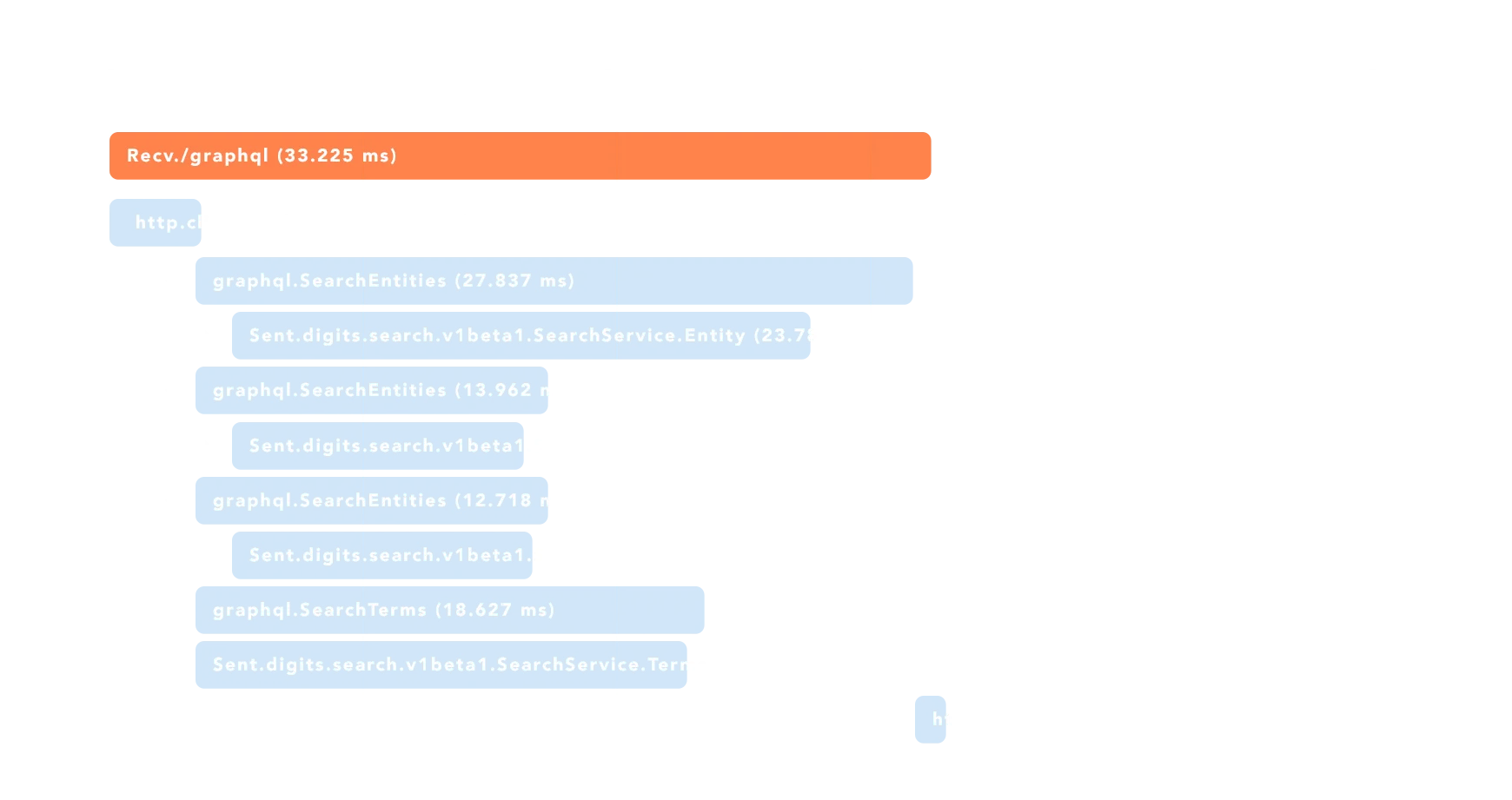
This makes search feel truly instant, and has led to some great customer feedback.
We’re also very pleased with Bleve’s underlying index implementation. In addition to excellent response latencies, its focus on memory usage means that our search service typically operates within low-tens-of-megabytes of memory under current usage, excluding mmap page caches.
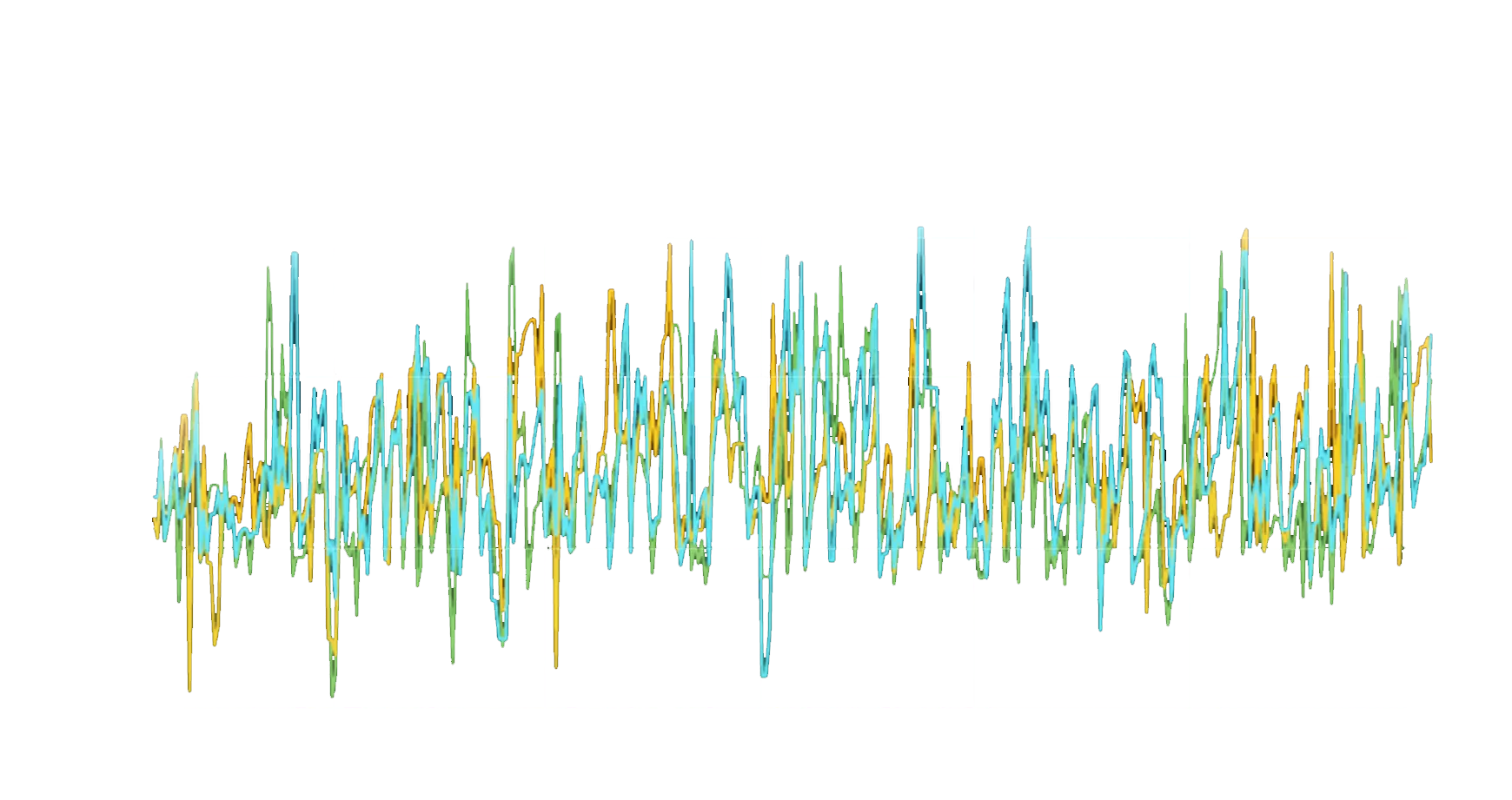
Compared with other search platforms’ out-of-the-box defaults, this is at least an order of magnitude more memory efficient for our use case of many small, isolated indexes. This efficiency means we don’t need to grow our Kubernetes cluster to make space for processes with a large baseline memory footprint.
We’re also pleased that we were able to use our existing authentication and authorization libraries, and tightly integrate them with our search index routing, so that every customer’s data is isolated and protected at a deep level.
Another decision that worked well in practice was to store the actual objects we need as a stored field in the index, which allows us to render beautiful search results without incurring object hydration latency penalties that we’d pay if we needed to make a cross-system call.
Finally, by building on Bleve’s composable query API, we were able to assemble queries in ways that solve for observed pain points. By architecting Search this way, we are able to easily build end-to-end tests for queries and their expected results, adding cases for bug fixes as we observe them.
Looking Forward
Although we’re happy with Search today, we’re not done. We’ve identified a number of future paths to make Search even better, such as investigating Bluge, a next-generation library built on Bleve’s core, which would give us more control over result ranking, query building, and aggregations.
We’re also exploring ways to further enhance query handling by incorporating machine learning to more deeply understand connections between what users are asking and patterns in their financial data. For example, we think we can make Search more conversational by extracting deeper semantic meaning from queries.
Join our team to push the limits of Search
If you’d like to learn how Digits users are interacting with Search, see something we missed, or have ideas on how to make it even better, we’d love to hear from you! We’re hiring engineers who are excited about taking real-world customer needs and iterating towards delightful, reliable product experiences.
We’re currently hiring software engineers and ML engineers, and we can’t wait to meet you.
Less technical? We have many more open positions to help accelerate our mission to revolutionize business finance.


