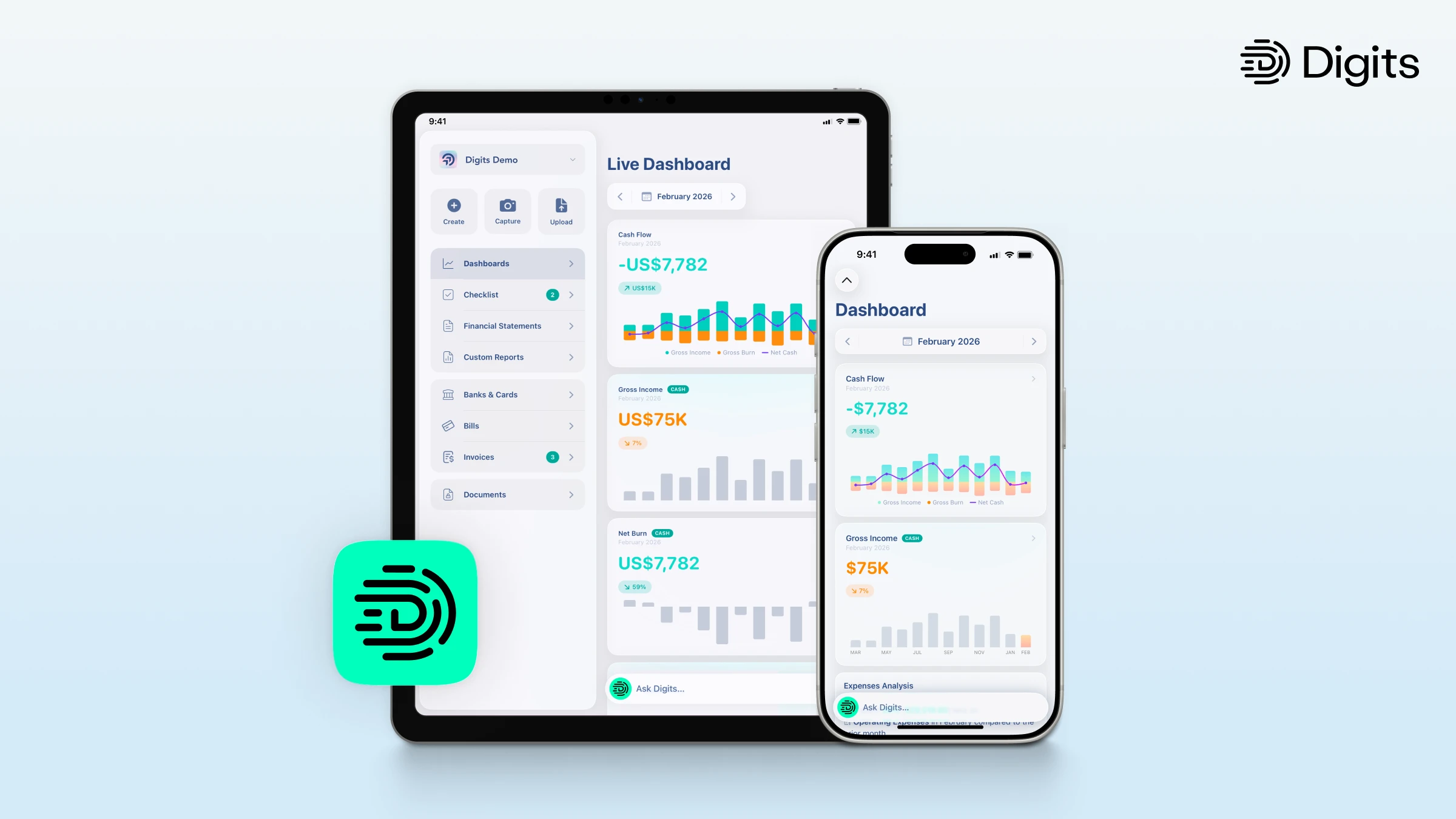
Introducing Digits for iPhone & iPad: Your finances, wherever you work.
Digits goes everywhere you do: Native apps bring real-time finance to every screen, with instant visibility, one-tap approvals, receipt capture, and an AI agent that answers questions from your live books.